
● It aims to stamp
a scarlet number risk score on EVERY child at birth.
● There is no opportunity for any family to opt-out or deny the use of their personal data.
● It’s literally computerized racial profiling: race and ethnicity are explicitly used to rate the risk that a child will be harmed.
● Developers say: Don’t worry, the data will be anonymized – but the promise is unenforceable.
First there was the Allegheny Family Screening Tool (AFST), an algorithm that uses a mass of data, mostly about poor people and disproportionately about nonwhite people, to cough up what amounts to a “scarlet number” risk score. When the county’s child abuse hotline receives a report alleging neglect, the score is used to guide screeners in deciding which children will have to endure the trauma of an investigation.
Key features of its implementation include:
● Ethically challenged ethics reviews.
● No informed consent – or any consent - for the use of the data as a policing tool.
● Deceptive
marketing.
● Evaluations
almost always done by the developers or commissioned by Allegheny County.
Hello, Baby

The county promises that Hello, Baby will be used only to target “preventive services.” Even if they keep this unenforceable promise, the services are likely to be delivered by mandated reporters of child abuse and neglect, who go in knowing an algorithm has labeled the family high-risk.
CJMR
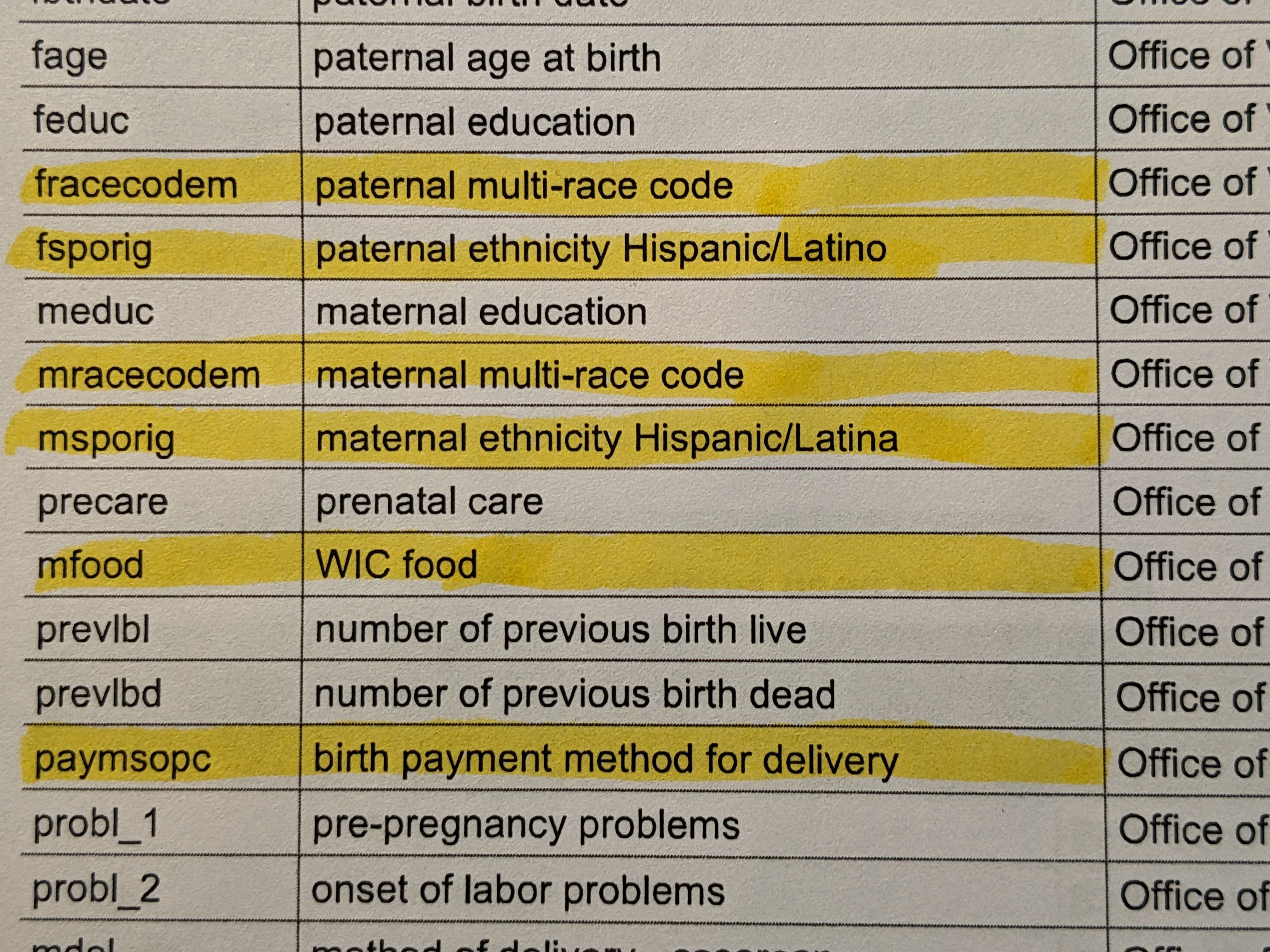 |
| Some of the data variables in the Cross Jurisdiction Model Replication Project |
And now comes the next all-too-logical progression. The same team that brought us AFST and Hello Baby, are part of the team offering up the most Orwellian algorithm yet: the Cross Jurisdiction Model Replication project.
Like “Hello, Baby,” CJMR generates a risk score for every child at birth. (The developers claim this is ok because, they say, in effect, the number is invisible. More about that below.) Unlike Hello, Baby there is no opt-out at all. And while with AFST the developers bragged about not explicitly using race (while using poverty), and with Hello Baby they claimed (falsely) that they weren’t using poverty, this time there’s no more let’s pretend. The use of race and poverty is out in the open.
● Paternal
multi-race code
● Material multi-race
code
● Paternal
ethnicity Hispanic/Latino
● Maternal ethnicity Hispanic/Latino
As for poverty, data variables include:
● “WIC food” (that
is, use of the Supplemental Nutrition Program for Women, Infants and Children).
And sure enough, the developers say, it works! How do they know? If this all weren’t so dangerous the answer would be laugh-out-loud funny: They know it works, they say, not because the algorithm was good at predicting actual child abuse, but because, in many cases, it was good at predicting whether a child would wind up in foster care!
But like everything else in family policing, the reasons children wind up in foster care are arbitrary, capricious, cruel – and subject to racial and class bias. As is so often the case with these algorithms, they are less prediction than self-fulfilling prophecy.

With CJMR there’s
no way to protect your family from government agencies taking your most basic,
and in some cases, most private data, and turning it against you. There is no chance for informed consent or
any kind of consent. And, of course,
there is nothing to show this actually prevents child abuse.
But don’t worry, the developers say. All of this is OK because the data are anonymized. That scarlet number risk score on your child is invisible, so no problem! The purpose of the algorithm, the developers say, is not to target individuals, but to target communities. The documents touting the algorithm are pretty vague, but they appear to be suggesting that if enough “high-risk” babies are from the same neighborhood that would be a good neighborhood for concentrating preventive services.
But since poverty itself is commonly confused with “neglect” we already know where the “high-risk” neighborhoods are – they’re the neighborhoods where poor people live. So all you need to do is find those neighborhoods – and send money. Not a lot of money either, since we know that remarkably small amounts of cash are enough to significantly reduce what family police agencies call “neglect.”
But for America’s giant child welfare industry of helping professionals, that spoils all the fun.
This was best explained decades ago by Malcolm Bush in his book Families in Distress:
“The recognition that the troubled family inhabits a context that is relevant to its problems suggests the possibility that the solution involves some humble tasks … This possibility is at odds with professional status. Professional status is not necessary for humble tasks … Changing the psyche was a grand task, and while the elaboration of theories past their practical benefit would not help families in trouble, it would allow social workers to hold up their heads in the professional meeting or the academic seminar.”
So it should come as no surprise that some of the biggest enthusiasts for scarlet number algorithms also are push a narrative of false complexity on a problem that really isn’t all that complex.
That’s best case. Worst case, they just want a rationale for taking away more kids.
The co-designer
And that brings us to the co-designer of all these algorithm projects, Emily Putnam-Hornstein. An algorithm can be only as unbiased as its designer, and Putnam-Hornstein has revealed increasing devotion both to tearing apart more families and to minimizing the racial bias problem in family policing has a racism problem. She has:
● Declared that "it is possible we don’t place enough children in foster care or early enough.”
● Called for forcing every parent reapplying for “public benefits” who has a child not otherwise seen by a mandated reporter to produce the child for a child abuse inspection in exchange for the financial aid.
● Not merely disagreed, but demeaned the work of Black activists.
● Taken pride in being part of a group that rushed to defend what it says is the right of a self-proclaimed “race realist” beloved by Tucker Carlson to rant about the inferiority of Black people – without one word condemning the content of those rants.
● Abandoned even the pretense of scholarly discourse on her Twitter feed, devoting it almost exclusively to lurid accounts of child abuse deaths.
So when Putnam-Hornstein helps design and promote an algorithm that explicitly uses race and income to determine “high risk” for child abuse, and when developers or users of that algorithm say, in effect, “Trust us, we’ll always keep the data anonymized,” that’s not good enough.
In fact, given that we already know how to target communities for prevention, the CJMR can serve no real purpose unless agencies using the algorithm stop anonymizing the data and use it to target individual families – and that’s what’s likely to happen as soon as there is a highly-publicized death of a child “known to the system” (like the ones in Putnam-Hornstein’s Twitter feed) in a state or locality that adopts the CJMR.
The only thing stopping that is a family police agency’s equivalent of a pinky-swear.